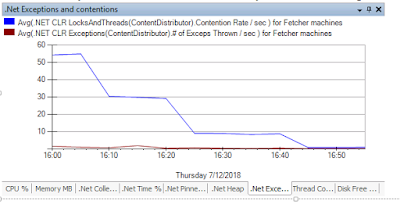
在这之前我对Contention Rate一无所知。 贴个有用的link here. 看了就晕菜。 为什么会想到Contention Rate, 源于我check in了总共五行code的counter change,然后导致了我们prod bed整个bed的contention rate 增加了20倍。与此同时一起增加的还有CPU和memory. 什么是Lock Contention Rate? 这是一个感人涕零的故事。。充分的说明了,自己挖的坑,自己得去填。 必须要记下这次的问题和解决方案。 对于每一个document, 我们会分配相应的partition 来选择upload的section. 但是由于store write rate的限制和fan out的bad impact, 我们只能够在client cache了requests 并且重新按照partition打包并对它进行限流。傻瓜的办法,限流工作就需要在partition level进行。我就对每个partition 都新建了一个rate gate. 每个rate gate是通过对一个semophore来进行相应的acquire和release从而达到限流的目的。在dev/int上还好,partition count都是千级别的level,可是到了production 上就抓瞎了。 partition整整涨了100倍。嘿嘿。然后的然后,我就发现了我们Product bed的cpu time涨了100倍。原因就是contention rate涨了100倍。 怎么办呢?不限流,store跪,限流了,我们跪。 再这里想补充一点,其实,我们好像也不会跪,因为32 cores的cup的cpu time应该是可以达到6400%。 即使单个service的cpu占用率400%。也用了不过8% 这个优化好像有点多余。虽然是好的,但在硬件足够强大的条件下,一切都是无所谓的。 本来想到的是把partition在upload的时候在rehash一下,可是如果rehash的不好,很有可能之前控制流量的那些功夫都白费了。在一个principal的指点下,which is so smart. 我可以对thread 本身加rate gate,然后保证在同一时刻只有一个partition在被一个...